1 year agoWhat is a Transformer? Transformers Explained - Working Principle (Transformer Tutorial)Electrical Electronics ApplicationsVerified
1 year agoHow do LLMs work? Next Word Prediction with the Transformer Architecture ExplainedWhat's AI
2 years agoHow Does an Electrical Service Work? Electrical Service Panels ExplainedElectrician UVerified
10 months agoIEEE 802.15.4 Wireless Personal Area Networks - EUI-64 JAB MAC Addresses ExplainedWatchman's Duty
2 years agoTransformer Memory as a Differentiable Search Index (Machine Learning Research Paper Explained)ykilcher
1 year agoWhat's Inside A Microwave Oven? || How To Dispose A Microwave Oven FAST And SAFE! Fully Explainedmediacreationclub1
3 years agoDeBERTa: Decoding-enhanced BERT with Disentangled Attention (Machine Learning Paper Explained)ykilcher
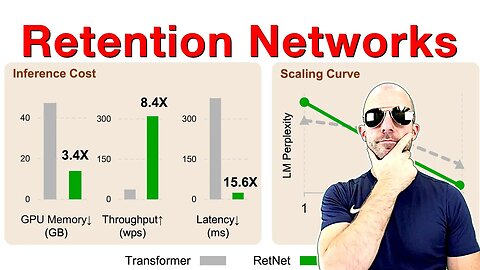
1 year agoRetentive Network: A Successor to Transformer for Large Language Models (Paper Explained)ykilcher
3 years agoDINO: Emerging Properties in Self-Supervised Vision Transformers (Facebook AI Research Explained)ykilcher
2 years agoROME: Locating and Editing Factual Associations in GPT (Paper Explained & Author Interview)ykilcher
3 years ago∞-former: Infinite Memory Transformer (aka Infty-Former / Infinity-Former, Research Paper Explained)ykilcher
3 years agoExpire-Span: Not All Memories are Created Equal: Learning to Forget by Expiring (Paper Explained)ykilcher
3 years agoPretrained Transformers as Universal Computation Engines (Machine Learning Research Paper Explained)ykilcher
3 years agoMLP-Mixer: An all-MLP Architecture for Vision (Machine Learning Research Paper Explained)ykilcher
3 years agoGLOM: How to represent part-whole hierarchies in a neural network (Geoff Hinton's Paper Explained)ykilcher
3 years agoFNet: Mixing Tokens with Fourier Transforms (Machine Learning Research Paper Explained)ykilcher
2 years agoCM3: A Causal Masked Multimodal Model of the Internet (Paper Explained w/ Author Interview)ykilcher
3 years agoFastformer: Additive Attention Can Be All You Need (Machine Learning Research Paper Explained)ykilcher