Author Interview - Typical Decoding for Natural Language Generation
#deeplearning #nlp #sampling
This is an interview with first author Clara Meister.
Paper review video hereé https://youtu.be/_EDr3ryrT_Y
Modern language models like T5 or GPT-3 achieve remarkably low perplexities on both training and validation data, yet when sampling from their output distributions, the generated text often seems dull and uninteresting. Various workarounds have been proposed, such as top-k sampling and nucleus sampling, but while these manage to somewhat improve the generated samples, they are hacky and unfounded. This paper introduces typical sampling, a new decoding method that is principled, effective, and can be implemented efficiently. Typical sampling turns away from sampling purely based on likelihood and explicitly finds a trade-off between generating high-probability samples and generating high-information samples. The paper connects typical sampling to psycholinguistic theories on human speech generation, and shows experimentally that typical sampling achieves much more diverse and interesting results than any of the current methods.
Sponsor: Introduction to Graph Neural Networks Course
https://www.graphneuralnets.com/p/int...
OUTLINE:
0:00 - Intro
0:35 - Sponsor: Introduction to GNNs Course (link in description)
1:30 - Why does sampling matter?
5:40 - What is a "typical" message?
8:35 - How do humans communicate?
10:25 - Why don't we just sample from the model's distribution?
15:30 - What happens if we condition on the information to transmit?
17:35 - Does typical sampling really represent human outputs?
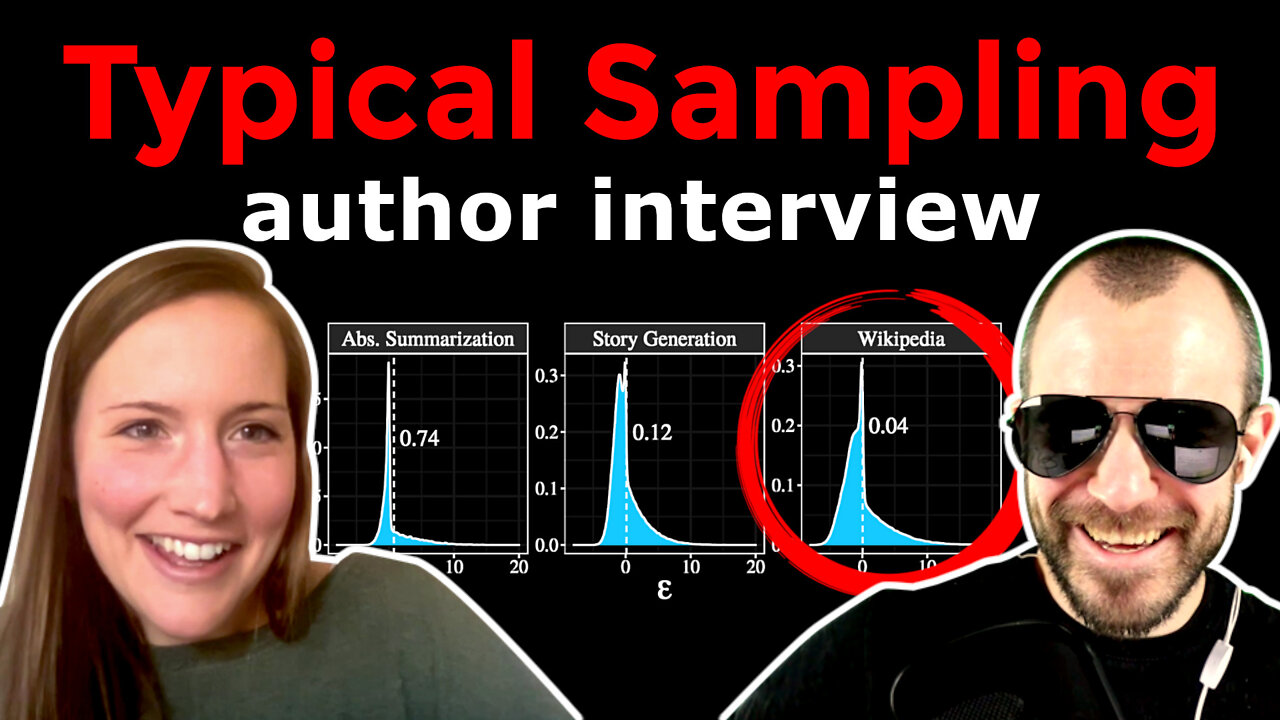
20:55 - What do the plots mean?
31:00 - Diving into the experimental results
39:15 - Are our training objectives wrong?
41:30 - Comparing typical sampling to top-k and nucleus sampling
44:50 - Explaining arbitrary engineering choices
47:20 - How can people get started with this?
Paper: https://arxiv.org/abs/2202.00666
Code: https://github.com/cimeister/typical-...
Abstract:
Despite achieving incredibly low perplexities on myriad natural language corpora, today's language models still often underperform when used to generate text. This dichotomy has puzzled the language generation community for the last few years. In this work, we posit that the abstraction of natural language as a communication channel (à la Shannon, 1948) can provide new insights into the behaviors of probabilistic language generators, e.g., why high-probability texts can be dull or repetitive. Humans use language as a means of communicating information, and do so in a simultaneously efficient and error-minimizing manner; they choose each word in a string with this (perhaps subconscious) goal in mind. We propose that generation from probabilistic models should mimic this behavior. Rather than always choosing words from the high-probability region of the distribution--which have a low Shannon information content--we sample from the set of words with information content close to the conditional entropy of our model, i.e., close to the expected information content. This decision criterion can be realized through a simple and efficient implementation, which we call typical sampling. Automatic and human evaluations show that, in comparison to nucleus and top-k sampling, typical sampling offers competitive performance in terms of quality while consistently reducing the number of degenerate repetitions.
Authors: Clara Meister, Tiago Pimentel, Gian Wiher, Ryan Cotterell
Links:
Merch: store.ykilcher.com
TabNine Code Completion (Referral): http://bit.ly/tabnine-yannick
YouTube: https://www.youtube.com/c/yannickilcher
Twitter: https://twitter.com/ykilcher
Discord: https://discord.gg/4H8xxDF
BitChute: https://www.bitchute.com/channel/yann...
LinkedIn: https://www.linkedin.com/in/ykilcher
BiliBili: https://space.bilibili.com/2017636191
If you want to support me, the best thing to do is to share out the content :)
If you want to support me financially (completely optional and voluntary, but a lot of people have asked for this):
SubscribeStar: https://www.subscribestar.com/yannick...
Patreon: https://www.patreon.com/yannickilcher
Bitcoin (BTC): bc1q49lsw3q325tr58ygf8sudx2dqfguclvngvy2cq
Ethereum (ETH): 0x7ad3513E3B8f66799f507Aa7874b1B0eBC7F85e2
Litecoin (LTC): LQW2TRyKYetVC8WjFkhpPhtpbDM4Vw7r9m
Monero (XMR): 4ACL8AGrEo5hAir8A9CeVrW8pEauWvnp1WnSDZxW7tziCDLhZAGsgzhRQABDnFy8yuM9fWJDviJPHKRjV4FWt19CJZN9D4n
-
 DVR
DVR
Chad Prather
18 hours agoThe Power You Cannot Buy: Motives, Power, and the Making of a True Disciple
24.1K16 -
 LIVE
LIVE
LFA TV
11 hours agoLIVE & BREAKING NEWS! | THURSDAY 12/04/25
3,245 watching -
 LIVE
LIVE
The Chris Salcedo Show
11 hours agoDispelling Narrative Over Facts On Racism
611 watching -
 16:09
16:09
T-SPLY
17 hours agoFederal Agents Arrest Non Citizen Police Officer — Department Hires Him BACK!
31.7K34 -
 12:55
12:55
World2Briggs
19 hours ago $3.73 earnedTop 10 States With The Worst Weather | Natural Disasters
12.5K -
 21:52
21:52
The King of Camo
20 hours agoGOALS 2026 Range Day
11.6K2 -
 48:22
48:22
A Cigar Hustlers Podcast Every Day
1 day agoEpisode 421 Cigar Hustlers Podcast Every Week Day Rage Bait
12.8K3 -
 2:05:49
2:05:49
BEK TV
1 day agoTrent Loos in the Morning - 12/04/2025
12.3K2 -
 2:55
2:55
Canadian Crooner
2 years agoPat Coolen | Christmas Blues
40.9K1 -
 LIVE
LIVE
The Bubba Army
23 hours agoPHOTOS REVEALED FROM EPSTEIN ISLAND! - Bubba the Love Sponge® Show | 12/04/25
1,177 watching