ExT5: Towards Extreme Multi-Task Scaling for Transfer Learning (Paper Explained)
#ext5 #transferlearning #exmix
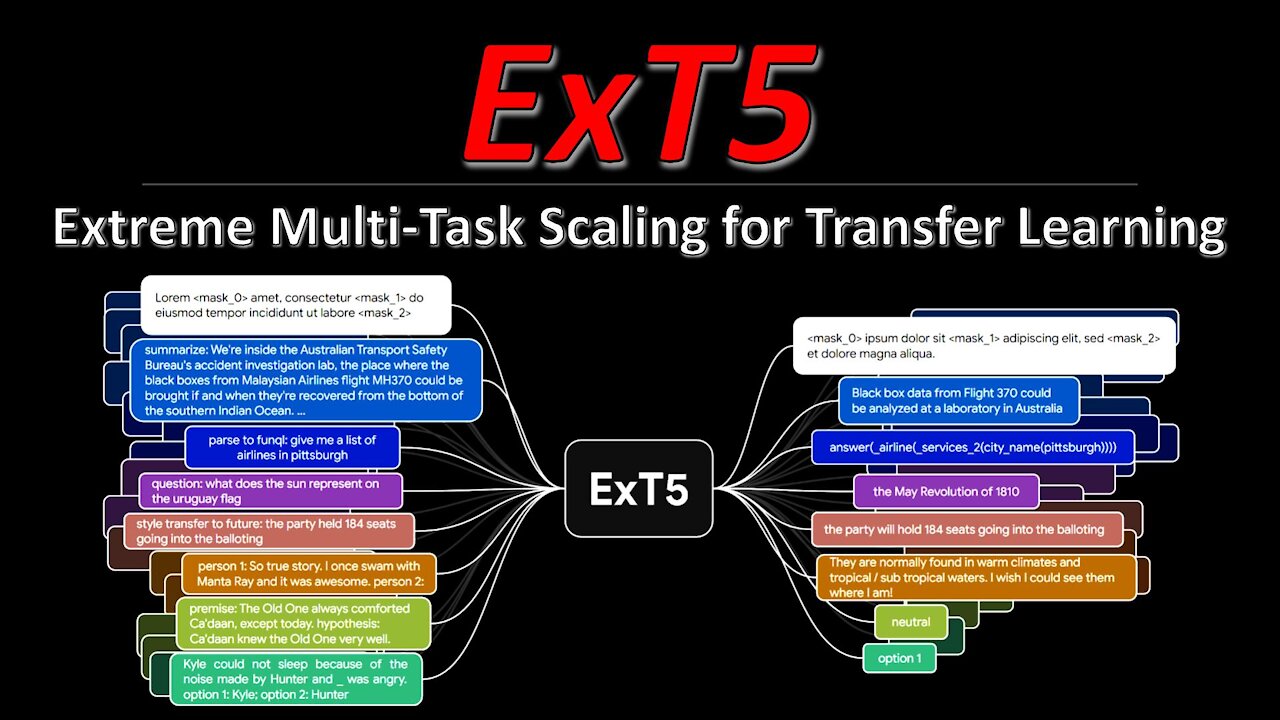
The T5 model has been a staple for NLP research for the last years. Both its size and its approach to formulate all NLP tasks as prompt-based language modeling make it a convenient choice to tackle new challenges and provides a strong baseline for most current datasets. ExT5 pushes T5 to its limits by pre-training not only on self-supervised mask filling, but also at the same time on 107 different supervised NLP tasks, which is their new ExMix dataset. The resulting model compares very favorably to T5 when fine-tuned to downstream tasks.
OUTLINE:
0:00 - Intro & Overview
2:15 - Recap: The T5 model
3:55 - The ExT5 model and task formulations
8:10 - ExMix dataset
9:35 - Do different tasks help each other?
16:50 - Which tasks should we include?
20:30 - Pre-Training vs Pre-Finetuning
23:00 - A few hypotheses about what's going on
27:20 - How much self-supervised data to use?
34:15 - More experimental results
38:40 - Conclusion & Summary
Paper: https://arxiv.org/abs/2111.10952
Abstract:
Despite the recent success of multi-task learning and transfer learning for natural language processing (NLP), few works have systematically studied the effect of scaling up the number of tasks during pre-training. Towards this goal, this paper introduces ExMix (Extreme Mixture): a massive collection of 107 supervised NLP tasks across diverse domains and task-families. Using ExMix, we study the effect of multi-task pre-training at the largest scale to date, and analyze co-training transfer amongst common families of tasks. Through this analysis, we show that manually curating an ideal set of tasks for multi-task pre-training is not straightforward, and that multi-task scaling can vastly improve models on its own. Finally, we propose ExT5: a model pre-trained using a multi-task objective of self-supervised span denoising and supervised ExMix. Via extensive experiments, we show that ExT5 outperforms strong T5 baselines on SuperGLUE, GEM, Rainbow, Closed-Book QA tasks, and several tasks outside of ExMix. ExT5 also significantly improves sample efficiency while pre-training.
Authors: Vamsi Aribandi, Yi Tay, Tal Schuster, Jinfeng Rao, Huaixiu Steven Zheng, Sanket Vaibhav Mehta, Honglei Zhuang, Vinh Q. Tran, Dara Bahri, Jianmo Ni, Jai Gupta, Kai Hui, Sebastian Ruder, Donald Metzler
Links:
TabNine Code Completion (Referral): http://bit.ly/tabnine-yannick
YouTube: https://www.youtube.com/c/yannickilcher
Twitter: https://twitter.com/ykilcher
Discord: https://discord.gg/4H8xxDF
BitChute: https://www.bitchute.com/channel/yann...
LinkedIn: https://www.linkedin.com/in/ykilcher
BiliBili: https://space.bilibili.com/2017636191
If you want to support me, the best thing to do is to share out the content :)
If you want to support me financially (completely optional and voluntary, but a lot of people have asked for this):
SubscribeStar: https://www.subscribestar.com/yannick...
Patreon: https://www.patreon.com/yannickilcher
Bitcoin (BTC): bc1q49lsw3q325tr58ygf8sudx2dqfguclvngvy2cq
Ethereum (ETH): 0x7ad3513E3B8f66799f507Aa7874b1B0eBC7F85e2
Litecoin (LTC): LQW2TRyKYetVC8WjFkhpPhtpbDM4Vw7r9m
Monero (XMR): 4ACL8AGrEo5hAir8A9CeVrW8pEauWvnp1WnSDZxW7tziCDLhZAGsgzhRQABDnFy8yuM9fWJDviJPHKRjV4FWt19CJZN9D4n
-
 LIVE
LIVE
meleegames
1 hour ago32X Roulette - 30 Years. 32 Games. 32X.
94 watching -
 LIVE
LIVE
BubbaSZN
1 hour ago🔴 LIVE - FARTNITE W/ @CATDOG & @CHEAP
32 watching -
 2:54:01
2:54:01
LadyDesireeMusic
4 hours ago $5.07 earnedCookin & Convo - Potato Soup, Ham & Apple Pie
31.5K2 -
 27:05
27:05
Robbi On The Record
7 hours ago $4.19 earnedThe Secret to Aging Strong: What Your Body’s Been Trying to Tell You
18.9K4 -
 3:27:19
3:27:19
bucketofish
5 hours ago///ARC Raiders || Loot, Scoot + Boogie
24.6K -
 LIVE
LIVE
iCheapshot
2 hours ago $0.25 earnedGames With Catdog | Fortnut Newb
40 watching -
 LIVE
LIVE
OhHiMark1776
3 hours ago🟢 11-09-25 ||||| Handling Hazardous Material ||||| SCP (2017)
29 watching -
 3:05:05
3:05:05
GamerGril
7 hours agoThere's A Killer Afoot 💞Until Dawn: The Final Gril💞
79.6K5 -
 5:41:25
5:41:25
GritsGG
9 hours ago#1 Most Warzone Wins 3953+!
45.2K3 -
 LIVE
LIVE
Spartan
5 hours agoGetting to DLC Boss on Stellar Blade (Hard Mode), then moving on to something else.
45 watching