Compiler From Scratch: Phase 1 - Tokenizer Generator 017: Fixing encoding issues, more build testing
Streamed on 2024-11-08 (https://www.twitch.tv/thediscouragerofhesitancy)
Zero Dependencies Programming!
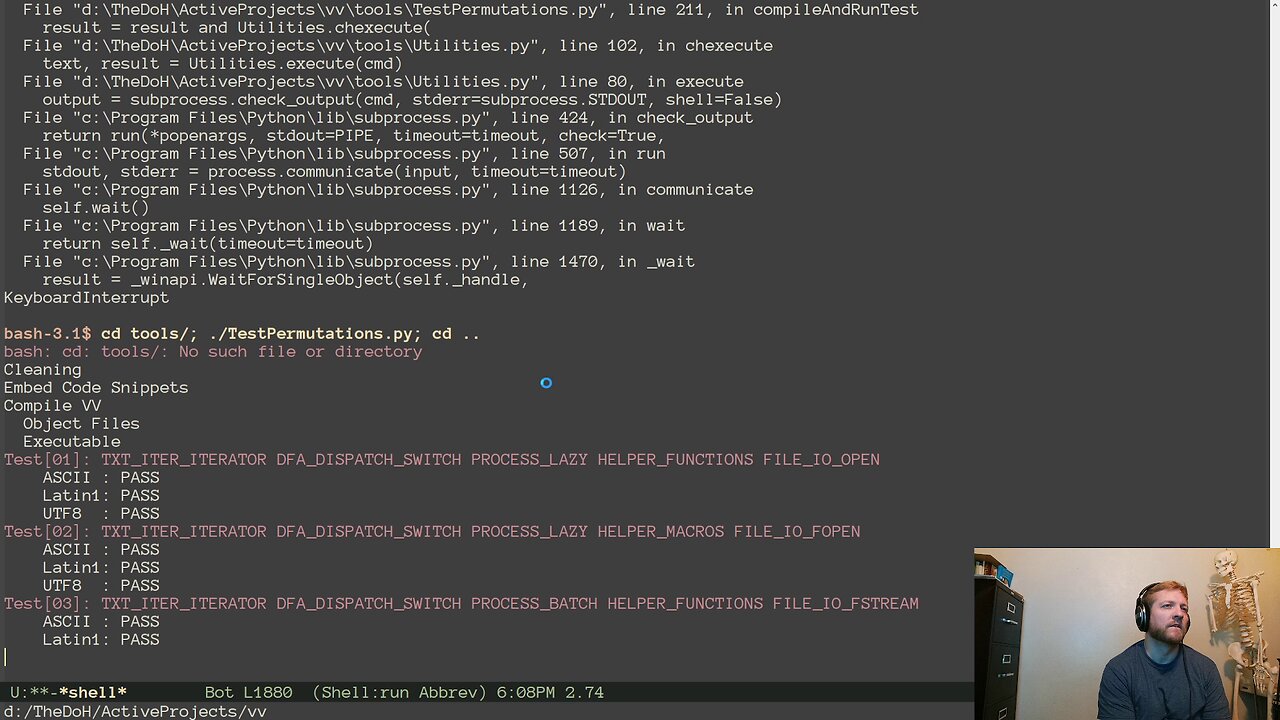
Picking up where we left off last week, the build permutation testing script is mostly working and has revealed that the different encodings supported aren't equally well supported. So I started out by turning the UTF8CharRef into just CharRef, where each CharRef has a flag for its own encoding, and a statically set default encoding. The VVProject sets the CharRef default encoding once it parses that encoding and then the rest of the parsing works the same as before. Fixing a couple of other things here and there got all the encodings to build.
I added some code for testing. Each encoding has a pre-set string to tokenize. Then the Tokenizer generated by our test script is compiled and run. Regardless of build option, the expected outputs are the same. It verifies the number of tokens, the number of lines and the length (in bytes) of the longest token.
With an actual test actually running it was time to run all the permutations. This testing revealed at the end of the stream that there is a bug when hitting the end of the text buffer while using LAZY processing. We tried a couple of things, but didn't have time to debug it. That is where we'll pick up next week.
-

VikingNilsen
10 hours ago🔴LIVE - VIKINGNILSEN - THE NEW PRELUDE - SOULFRAME
136 -
 7:45
7:45
Colion Noir
1 day agoThey Made Glock “Unconvertible” To Please Politicians, Guess What The Internet Did?
9.31K21 -
 23:42
23:42
The Kevin Trudeau Show Limitless
1 day agoThe Brotherhood’s Ancient Mirror Code Revealed
12.5K6 -
 11:21
11:21
Degenerate Jay
1 day ago $6.96 earnedSilent Hill's New Movie Could Be A Bad Idea...
19.9K3 -
![[Ep 801] Dems Setup & Disgusting Response to DC Tragedy | Giving Thanks With Rush](https://1a-1791.com/video/fwe2/79/s8/1/2/t/F/D/2tFDz.0kob-small-Ep-801-Dems-Setup-and-Disgu.jpg) 3:19:35
3:19:35
The Nunn Report - w/ Dan Nunn
5 hours ago[Ep 801] Dems Setup & Disgusting Response to DC Tragedy | Giving Thanks With Rush
13.1K9 -
 20:23
20:23
Neil McCoy-Ward
7 hours ago🚨 She Wasn’t Ready for This (TOTAL PUBLIC HUMILIATION!)
28.5K18 -
 18:46
18:46
ThinkStory
1 day agoIT: WELCOME TO DERRY Episode 5 Breakdown, Theories, & Details You Missed!
28.9K -
 2:23:05
2:23:05
Badlands Media
15 hours agoBadlands Daily – Nov. 27, 2025
132K41 -
 6:20:00
6:20:00
FusedAegisTV
10 hours agoFUSEDAEGIS | They Put A Freakin' Blue Mage In THIS | Expedition 33 PART V
50K -
 1:16:04
1:16:04
Rebel News
7 hours agoHealth-care collapsing, Bloc says Quebec sends Alberta $, US Ambassador's advice | Rebel Roundup
36K27