Compiler From Scratch: Phase 1 - Tokenizer Generator 015: Finishing Lazy Token Evaluation
Streamed on 2024-10-25 (https://www.twitch.tv/thediscouragerofhesitancy)
Zero Dependencies Programming!
Last week we started with the Lazy evaluation build option, but didn't have time to finish it. So today we finished it.
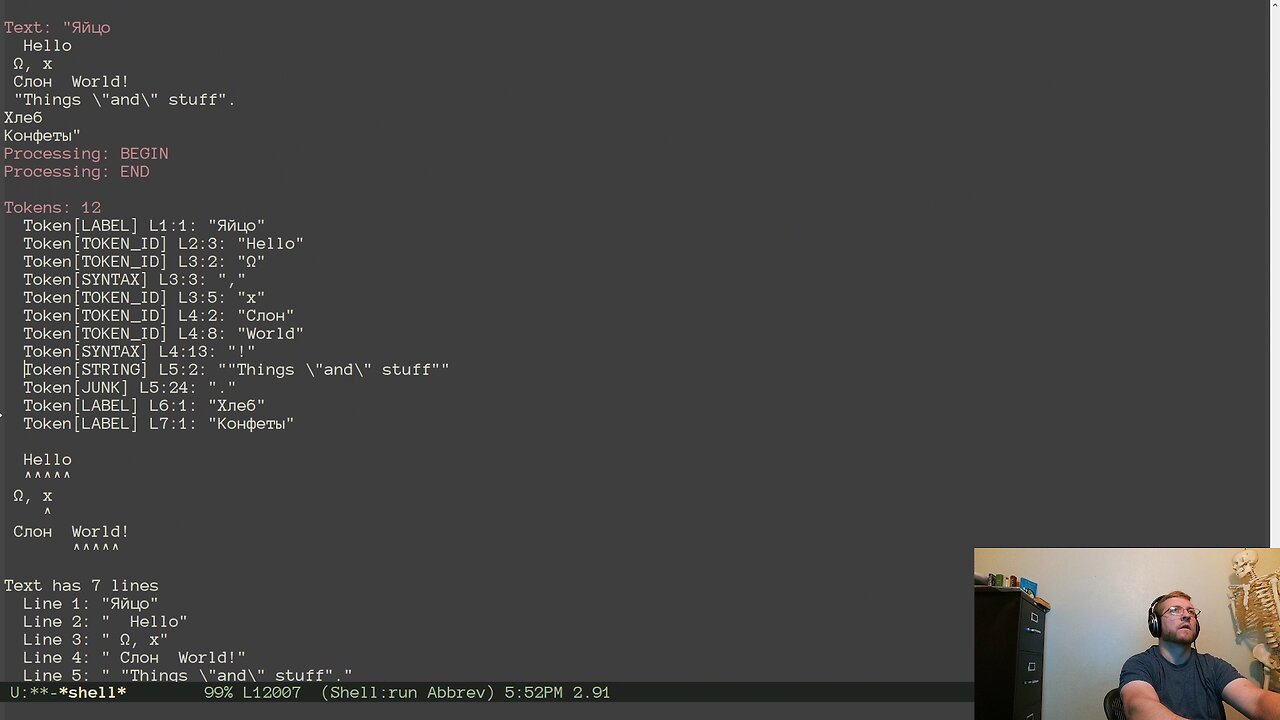
As I dug in, it became clear that I needed a way to track execution of the regex DFA states to see what was happening and when. So I started coding that in. However, that introduced a bug that caused things to crash so hard that there was no debug information. After a log to printf debugging, I narrowed it down to a single snippet of text that was being written out to a file. For some reason, copying a single word out by offset using snprintf was exploding if the source text had a "%" anywhere in it . The "%" was not in the offset/count region that was actually being copied from at all. I replaced the call to snprintf with strncpy and everything worked again. It just makes me sad how much time it took to find the reason and the solution.
Once we were back up and running there was a bit of fiddling to finish off Lazy token evaluation. There are a few differences in the way the process flows when batch processing vs lazy processing, but I found them one at a time (greatly aided by the trace log of the tokenizing process). A bit of testing with other performance flags, an update to the macros in the resulting file, and lazy processing is reasonably working for all of the build options we tested.
Next week we need to write a script to test the different combinations more automatically and efficiently. There are a lot of build configuration options now.
-
 7:45
7:45
Colion Noir
1 day agoThey Made Glock “Unconvertible” To Please Politicians, Guess What The Internet Did?
3.7K18 -
 24:55
24:55
Jasmin Laine
1 day agoCarney BRAGS About ‘Investment’—Poilievre Drops a FACT That Stops the Room
1.43K10 -
 23:42
23:42
The Kevin Trudeau Show Limitless
1 day agoThe Brotherhood’s Ancient Mirror Code Revealed
4.46K5 -
 11:21
11:21
Degenerate Jay
1 day ago $4.02 earnedSilent Hill's New Movie Could Be A Bad Idea...
8.44K3 -
![[Ep 801] Dems Setup & Disgusting Response to DC Tragedy | Giving Thanks With Rush](https://1a-1791.com/video/fwe2/79/s8/1/2/t/F/D/2tFDz.0kob-small-Ep-801-Dems-Setup-and-Disgu.jpg) LIVE
LIVE
The Nunn Report - w/ Dan Nunn
3 hours ago[Ep 801] Dems Setup & Disgusting Response to DC Tragedy | Giving Thanks With Rush
65 watching -
 20:23
20:23
Neil McCoy-Ward
6 hours ago🚨 She Wasn’t Ready for This (TOTAL PUBLIC HUMILIATION!)
16.1K12 -
 18:46
18:46
ThinkStory
1 day agoIT: WELCOME TO DERRY Episode 5 Breakdown, Theories, & Details You Missed!
19.1K -
 2:23:05
2:23:05
Badlands Media
14 hours agoBadlands Daily – Nov. 27, 2025
120K39 -
 6:20:00
6:20:00
FusedAegisTV
8 hours agoFUSEDAEGIS | They Put A Freakin' Blue Mage In THIS | Expedition 33 PART V
43K -
 1:16:04
1:16:04
Rebel News
5 hours agoHealth-care collapsing, Bloc says Quebec sends Alberta $, US Ambassador's advice | Rebel Roundup
26.8K24