Scaling Transformer to 1M tokens and beyond with RMT (Paper Explained)
#ai #transformer #gpt4
This paper promises to scale transformers to 1 million tokens and beyond. We take a look at the technique behind it: The Recurrent Memory Transformer, and what its strenghts and weaknesses are.
OUTLINE:
0:00 - Intro
2:15 - Transformers on long sequences
4:30 - Tasks considered
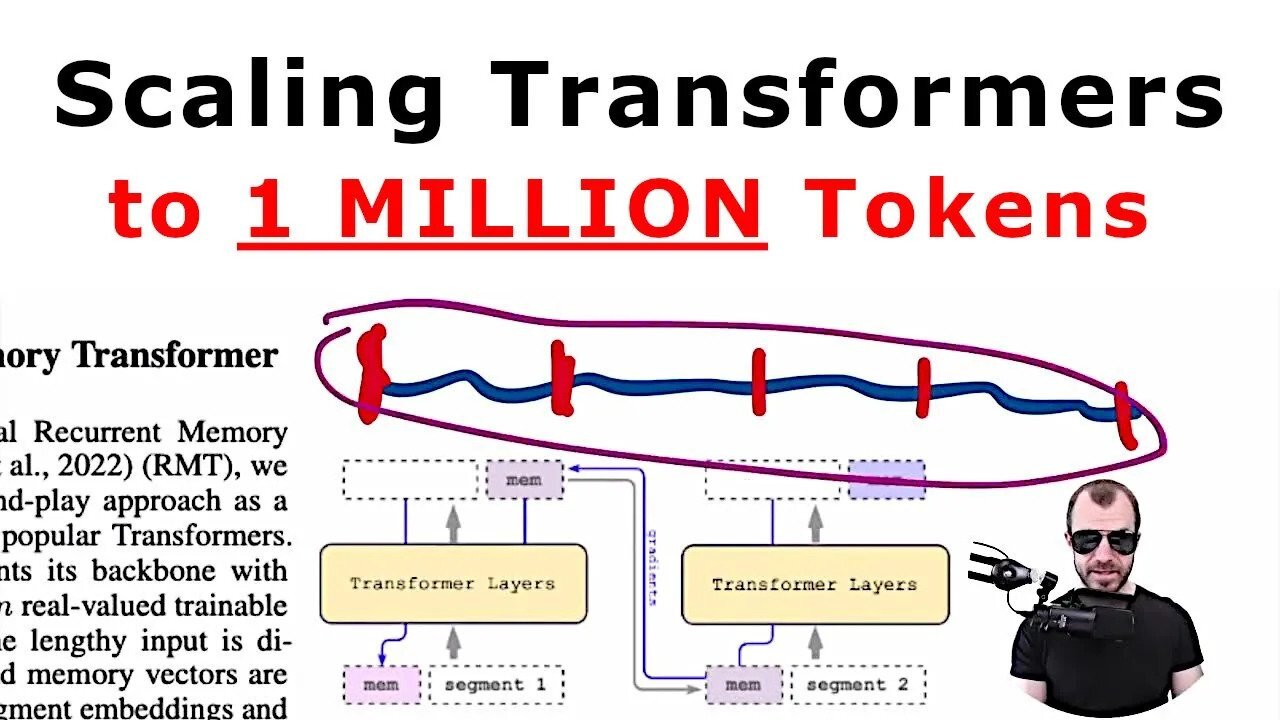
8:00 - Recurrent Memory Transformer
19:40 - Experiments on scaling and attention maps
24:00 - Conclusion
Paper: https://arxiv.org/abs/2304.11062
Abstract:
This technical report presents the application of a recurrent memory to extend the context length of BERT, one of the most effective Transformer-based models in natural language processing. By leveraging the Recurrent Memory Transformer architecture, we have successfully increased the model's effective context length to an unprecedented two million tokens, while maintaining high memory retrieval accuracy. Our method allows for the storage and processing of both local and global information and enables information flow between segments of the input sequence through the use of recurrence. Our experiments demonstrate the effectiveness of our approach, which holds significant potential to enhance long-term dependency handling in natural language understanding and generation tasks as well as enable large-scale context processing for memory-intensive applications.
Authors: Aydar Bulatov, Yuri Kuratov, Mikhail S. Burtsev
Links:
Homepage: https://ykilcher.com
Merch: https://ykilcher.com/merch
YouTube: https://www.youtube.com/c/yannickilcher
Twitter: https://twitter.com/ykilcher
Discord: https://ykilcher.com/discord
LinkedIn: https://www.linkedin.com/in/ykilcher
If you want to support me, the best thing to do is to share out the content :)
If you want to support me financially (completely optional and voluntary, but a lot of people have asked for this):
SubscribeStar: https://www.subscribestar.com/yannickilcher
Patreon: https://www.patreon.com/yannickilcher
Bitcoin (BTC): bc1q49lsw3q325tr58ygf8sudx2dqfguclvngvy2cq
Ethereum (ETH): 0x7ad3513E3B8f66799f507Aa7874b1B0eBC7F85e2
Litecoin (LTC): LQW2TRyKYetVC8WjFkhpPhtpbDM4Vw7r9m
Monero (XMR): 4ACL8AGrEo5hAir8A9CeVrW8pEauWvnp1WnSDZxW7tziCDLhZAGsgzhRQABDnFy8yuM9fWJDviJPHKRjV4FWt19CJZN9D4n
-
 1:02:49
1:02:49
TheCrucible
2 hours agoThe Extravaganza! EP: 70 (12/04/25)
37.3K3 -
 2:59:04
2:59:04
Redacted News
3 hours agoBREAKING! PIPE BOMB SUSPECT BRIAN COLE ARRESTED, FBI COVER-UP GOES NUCLEAR | Redacted News
122K43 -
 35:24
35:24
Stephen Gardner
2 hours ago🔥Tucker's BOMBSHELL warning + Trump FBI Makes BIG ARREST!!
20.3K21 -
 1:16:48
1:16:48
vivafrei
4 hours agoFBI Announces ARREST of Suspected Pipe Bomber! Judge Boasberg Should be IMPEACHED! & MORE!
82.4K49 -
 34:26
34:26
Misfits Mania
8 hours ago $14.22 earnedMISFITS MANIA: Launch Press Conference
152K23 -
 33:29
33:29
Donald Trump Jr.
7 hours agoLive With FBI Director Kash Patel, Breaking News!! | Triggered Ep.297
241K229 -
 1:22:59
1:22:59
The Quartering
5 hours agoJ6 Pipe Bomber Arrested, Candace Owens TPUSA Debate Predictions & My Staff Caused A Lawsuit!
107K61 -
 LIVE
LIVE
Dr Disrespect
8 hours ago🔴LIVE - DR DISRESPECT - WARZONE x BLACK OPS 7 - SEASON 1 INTEGRATION
1,023 watching -
 26:36
26:36
Jasmin Laine
3 hours agoTrump SILENCES Liberal Canada—CEO’s Oval Office Bombshell STUNS Ottawa
12.7K11 -
 27:03
27:03
The Kevin Trudeau Show Limitless
1 day agoThey're Not Hiding Aliens. They're Hiding This.
25.5K34