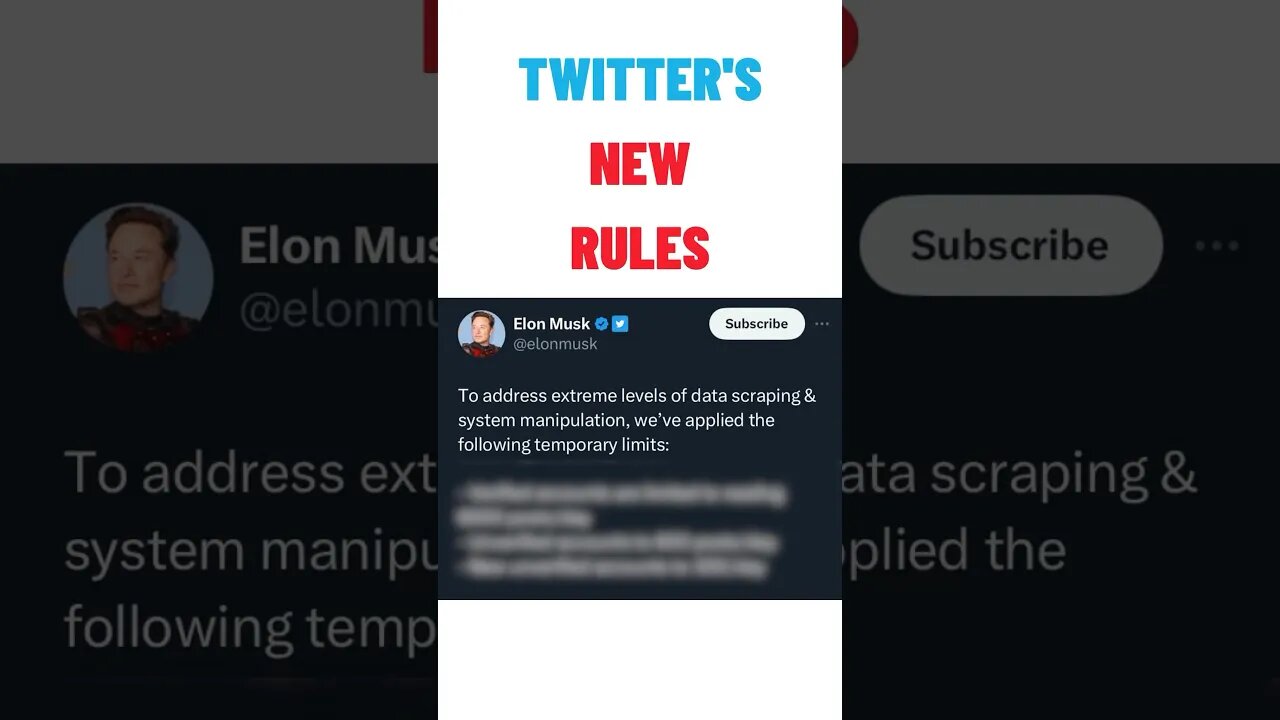
Twitter's New Limits Has Everyone Furious! 🤬 #news #technology #twitter
In order to limit data scraping which costs Twitter money, the company has implemented some new limitations.
What is Data Scraping?
Data scraping refers to the process of extracting or "scraping" data from websites, typically using automated tools or scripts. It involves retrieving information from web pages and saving it for further analysis or use. Data scraping can be performed for various purposes, including market research, data analysis, content aggregation, or building applications that rely on up-to-date data.
When it comes to Twitter, data scraping can potentially cost the company money in a few ways:
Infrastructure costs: Data scraping puts a strain on Twitter's servers and infrastructure. When multiple automated requests are made to extract data from Twitter's platform, it increases the server load and consumes system resources. As a result, Twitter may need to allocate additional resources to handle the increased traffic, leading to higher infrastructure costs.
Bandwidth costs: Data scraping involves transferring a significant amount of data from Twitter's servers to the scraper's end. This data transfer consumes bandwidth, and Twitter incurs the associated costs for transmitting that data over its network infrastructure.
User experience and ad revenue: Data scraping can negatively impact the user experience on Twitter. Frequent scraping activities can cause slower response times, increased downtime, or other disruptions for users accessing the platform. This can lead to user dissatisfaction and potentially drive users away from the platform, resulting in reduced user engagement and potentially impacting Twitter's ad revenue.
Misuse of data: Scraped data can be used for various purposes, including building competing products or services, conducting market research, or selling the data to third parties. If unauthorized scraping activities result in the unauthorized use or distribution of Twitter's data, it can harm the company's competitive advantage, intellectual property rights, and potential revenue streams.
To mitigate these risks, Twitter has implemented various measures to prevent unauthorized data scraping, including rate limits, API access restrictions, and terms of service that prohibit scraping activities without proper authorization. Violating these terms can lead to legal consequences, including potential legal action by Twitter to protect its platform and data.
Twitter's latest rules limit Verified users to be able to read 6000 posts per day, unverified users, 600 posts per day and new unverified users can only read 300 posts per day.
Do you think these limits will be good or bad for Twitter in the long-run?
-
 LIVE
LIVE
Rallied
1 hour agoWarzone Solo Challenges All Day w/ Ral
81 watching -
 LIVE
LIVE
Melonie Mac
1 hour agoGo Boom Live Ep 59!
179 watching -
 45:07
45:07
MattMorseTV
1 hour ago🔴Tulsi just DROPPED a BOMBSHELL.🔴
7236 -
 16:01
16:01
AndresRestart
7 hours agoNEW Metroid Prime 4 Nintendo Switch 2 Screenshots Graphics Comparison & Analysis!
30 -
 17:02
17:02
Metal Detecting WWII Battlegrounds
2 days ago $0.02 earnedPersonal Items of Wehrmacht Soldiers Discovered - Eastern Front
62 -
 LIVE
LIVE
LFA TV
12 hours agoLFA TV ALL DAY STREAM - WEDNESDAY 8/13/25
874 watching -
 7:12:36
7:12:36
Dr Disrespect
8 hours ago🔴LIVE - DR DISRESPECT - THE FINALS - THE MOST UNDERRATED FPS GAME EVER?
159K16 -
 LIVE
LIVE
Barry Cunningham
5 hours agoCOULD PRESIDENT TRUMP HAVE A MUCH BIGGER REASON FOR TAKING OVER WASHINGTON D.C.?
3,291 watching -
 LIVE
LIVE
RiftTV
4 hours agoFuentes vs. THE WORLD? Tucker and Candace RAMP UP Attacks | The Rift | Guest: Simon Goddek
630 watching -
 21:26
21:26
Paul Barron Network
5 days agoGTA 6 Stablecoin Potential🚀Animoca's MASSIVE Crypto Treasury!🔥Yat Siu INTERVIEW
53